
Quantopian proporciona un entorno idóneo implementar Data Science en el Trading
» Data Science en las Finanzas
Seguramente habrán oído hablar del término data science: es una de las tendencias disruptivas que están transformando el mundo, y las finanzas no permanecen ajenas a ello. Hay un número creciente de matemáticos, programadores, ingenieros de datos y físicos, tradicionalmente ajenos a la actividad inversora, que aprovechan la ubicuidad de computación potente y barata, así como la disponibilidad de datos financieros para codificar sus propias estrategias de trading. Esta nueva generación de, si me permiten el apelativo cariñoso, “traders manitas” son la versión actualizada del ejército de day traders que emergió durante el market boom de los años 90 y son capaces de crear sus propias estrategias con mínimas instrucciones.
El Lenguaje: Python
Entre ellos se está estableciendo como su estándar de facto Python, el lenguaje apadrinado por Google y tantas otras factorías de data science. Las razones son tres: se trata de un lenguaje moderno, flexible, expresivo, que permite realizar asombrosas transformaciones en muchas menos líneas que otros lenguajes más encorsetados como C# o Java, y eso es importante: hoy en día lo realmente caro es el tiempo de programación (el coste del talento), no el tiempo de ejecución. Esto tradicionalmente conllevaba una ejecución comparativamente más lenta, pero en el caso de Python, debido a su cercanía con C, se ha hecho un esfuerzo particularmente intenso para acelerar las computaciones críticas (por ejemplo, operaciones matriciales) y dirigirlas a las partes del sistema que pueden realizar mejor la tarea (por ejemplo, la Unidad de Procesamiento Gráfica, idónea para trabajar con vectores), resultando en una ejecución que iguala o supera la de los lenguajes tradicionales. Finalmente, Python cuenta con abundantes librerías para cálculos científicos, manipulación de datos, e incluso inteligencia artificial, todas ellas gratuitas y continuamente mejoradas por una fuerte comunidad profesional, nada académica.
La IDE: Quantopian
De todas formas, salir de los confortables bordes de una IDE de trading tradicional como VisualChart, TradeStation, NinjaTrader o MetaTrader resulta difícil, por mucho que entendamos los beneficios que nos puede aportar en nuestro trading. Porque más allá de aprender el nuevo lenguaje de programación, Python, nos tendremos que ocupar de mantener todo el entorno de trabajo que esas plataformas nos proporcionan de forma casi invisible: obtener los datos históricos, analizarlos en un entorno controlado, llevar a cabo simulaciones de backtest, determinar estrategias algorítmicas, ejecutar posiciones a tiempo real, computar resultados, pulir y repetir… más de lo que está al alcance de la mayoría.
Sin embargo, hay opciones mejores: están apareciendo plataformas online que reemplazan la labor tradicional de dichas IDES, ofreciendo toda esa funcionalidad y permitiendo que el “trader manitas” se concentre en lo realmente importante: usar Python para crear estrategias automatizadas que sean rentables. En esta reseña presentamos la plataforma líder a nivel mundial, Quantopian, y de cómo podemos trabajar con ella implementando una simple estrategia de ejemplo.
Tras el registro gratuito en Quantopian (http://www.quantopian.com), podrá acceder a los servicios de la plataforma. Nuestro espacio de trabajo se encuentra dividido en dos opciones, ambas contenidas bajo el epígrafe “My Code”.
Investigación: Notebooks

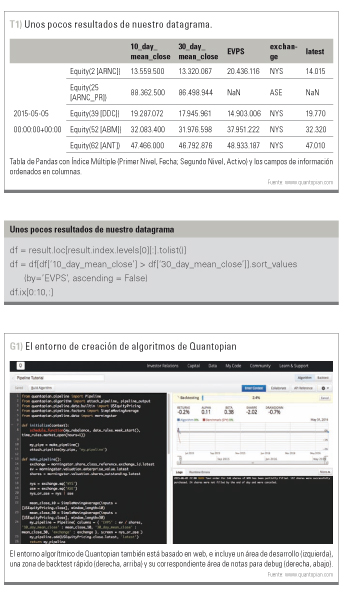
La primera de ellas es “Notebooks”: aquí es donde realizaremos nuestro trabajo de investigación, pudiendo combinar para ello múltiples fuentes de datos y toda la potencia analítica de Python, ya que se trata de una implementación propia de Quantopian de los populares Notebooks de Jupyter que permiten usar iPython para programar… ¡directamente en el propio navegador! Obteniendo nuestros resultados a tiempo real. Para entender la idiosincrasia particular de trabajar con Quantopian, vamos a escribir el siguiente código en la primera celda:
Vayamos por partes. Quantopian estructura la obtención y manipulación de datos a través de Pipelines. En este caso estamos solicitando un Pipeline con los datos de todas las compañías americanas, que inmediatamente filtramos para focalizarnos sólo en las compañías listadas en el NYS y el ASE, usando un screen sobre el pipeline. También computamos el valor por acción de cada compañía, dividiendo el Enterprise Value (que es la capitalización de mercado más la deuda, menos el contado) por el número de acciones en circulación, datos todos ellos que obtenemos de Morningstar. Morningstar cuenta con muchos otros datos fundamentales que podemos explorar; lo veremos fácilmente si escribimos morningstar. y pulsamos tabulador detrás del punto (activando así el sistema de autocompletado de Jupyter). Por otro lado, también calculamos un par de medias móviles sobre el precio de cierre, una lenta de 30 días y una rápida de 10 y lo incluímos al pipeline junto con el último precio disponible para cada activo.
Si ejecutamos el código obtendremos algo parecido a lo siguiente:
Se trata de un datagrama de Pandas, indexado primero por fecha, y luego por compañía, que contiene de forma tabular, cual Excel, toda la información que hemos solicitado. Ahora, si por ejemplo queremos obtener, para la primera fecha, los diez valores que tienen el EVPS más alto y en el que la SMA rápida está por encima de la SMA lenta, es tan sencillo como:
La línea inicial aísla la primera fecha (posicionalmente, para evitar usar fechas específicas que pueden cambiar), la segunda filtra por SMA y ordena por EVPS, mientras que la tercera toma las 10 primeras. Fíjese que hubiésemos podido incluso simplificar restando ambas SMAs en el Pipeline y discerniendo valores negativos o positivos para nuestro indicador. Queda como ejercicio doméstico. No tenemos espacio aquí para explorar las inmensas posibilidades de manipulación que ofrece Pandas, así que nos focalizaremos en cómo usar esta información en producción.
Operativa: Algoritmos
Vamos ahora a trasladar nuestro Pipeline a “Algorithms”, la parte de Quantopian donde podemos implementar, ejecutar y hacer un backtest de nuestra estrategia. El entorno aquí debería ser familiar para cualquier persona que ha trabajado con una IDE tradicional. Escribiremos lo siguiente en un nuevo algoritmo (ve cuadro):
Vemos que nuestro Pipeline se encuentra en la función make_pipeline, a la cual llamamos al inicializar el algoritmo, pero en lugar de usar run_pipline en este caso la adjuntamos mediante attach_pipeline. Antes del inicio de cada sesión de trading, la función personalizada before_trading_start se encargará de recibir el datagrama correspondiente, analizarlo, y guardar las diez acciones seleccionadas para inversión en la variable de entorno context.assets.
Nuestra estrategia de inversión, simple en extremo, consistirá en tomar dicha selección al principio de cada semana y rebalancear nuestra cartera en base a las acciones elegidas, hasta un máximo de diez, invirtiendo una parte proporcional de nuestro capital y sin usar ningún tipo de apalancamiento. Esa es la tarea realizada por la función my_rebalance, que opera mediante la función simplificada order_target_percent, entre las varias opciones para actuar en el mercado con las que cuenta Quantopian.
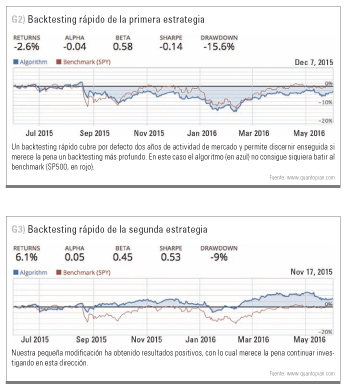
Si ejecutamos nuestro código pulsando “Build Algorithm” podemos maravillarnos con lo fácil que es probar estrategias, si bien no con los resultados: nuestro algoritmo no consigue batir el benchmark puesto por el SPY durante el periodo 2015-2016. Ahora bien, vamos a hacer un simple cambio colocando esta línea a continuación de nuestro pipeline_output:
df = df.sort_values(by=’EVPS’, ascending = False).ix[0:10,:]
En lugar de buscar cruces de SMA y ordenar por EVPS a continuación, esta línea va a limitar la búsqueda sólo a las diez acciones con mayor EVPS en el momento, y sólo entre ellas buscar dichos cruces. Es decir, de alguna manera estamos primando calidad del activo por encima de momento de mercado. Si ahora ejecutamos el código de nuevo podemos ver que obtenemos mejores resultados, batiendo al benchmark.
Sin duda tanto la estrategia como el código dejan mucho que desear, empezando por el hecho de que usamos sort_value dos veces de forma innecesaria, etc pero nos sirve como ejemplo en este breve artículo para experimentar la plasticidad de Python, las posibilidades de combinar indicadores técnicos con fundamentales, y la asombrosa velocidad a la que podemos probar nuestras ideas en Quantopian. Ahora el volante está en sus manos: ejecute un backtest completo en una serie temporal más amplia y significativa, modifique el código con sus propias metodologías y sírvase de los tutoriales y foros online de Quantopian para ampliar sus conocimientos. Conduzca con cuidado y ¡diviértase!

Esta reseña ha sido posible gracias a Isaac de la Peña, de Ágora EAFI «